안녕하세요.
Meta에서 2023.07.18 LLaMa2를 공개합니다.
지금은 공개일로부터 약 7일이 지났네요.
이제는 일주일이면 많이 늦어진 상황이 되고 있습니다.
세상은 정말 너무 빠르게 흘러가고 있기 때문에 놓치면 안됩니다.
오늘도 간랸한 논문 리뷰 남겨보겠습니다.
| Paper link | https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/ |
LLaMa1과 달리 LLaMa2 달라진 점
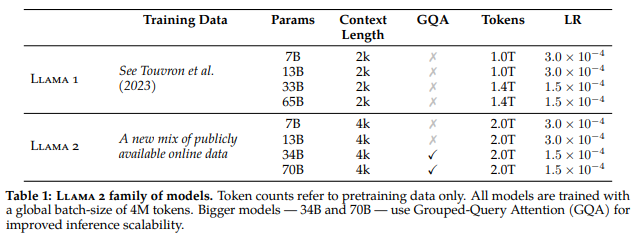
- 훈련 데이터 더 public 데이터로 늘렸고
- 파라미터 7B, 13B, 34B, 70B
- context length 문장길이 2배 늘렸고
- GQA: Group Q&A 가능하고
- Tockens 1조->2조 늘었고
성적
이런 변화 때문인지,
발표 공개 당일 1등,
현재 일주일이 지난 지금 3등을 유지하고 있습니다.
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?ref=t4eh0.com

한국회사, upstage, 는 그 바로 아래 4등을 유지하고 있습니다.
1등은 stability ai 회사로 UK회사인데 유명한 stable defusion을 공개했었죠!
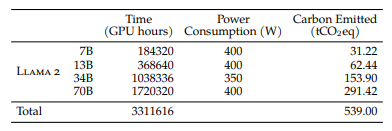
Training
- Meta's Research Super Cluster (NVIDIA A100s)
- GPU max 2000 - 35days (500억)
- LLaMa2 70B - A100 80GB, 1720320h
CO2 Emission
Fine-tuning
- Supervised fine-tunning
- 다양한 소스 긁어왔지만 다양성 부족
- SI업체 질 좋은 데이터셋 사용하니 양 적어도 훨씬 좋다.
- Reinforcement Learning with Human Feedback
- 폭탄 만드는 법 알려줘 같은 질문에는 답을 하지 못하도록
- 사람의 주입 정보로 모델의 행동을 align 시키는 학습단계
- A,B 둘다 안전하다 > A만 안전하다 > B만 안전하다 > 둘 다 안전하지않다 등 답변 가능하도록
- System Message for Multi-Turn Consistency
- 초기 대화 잊어먹는 문제 있어서 ghost attention(GATT) 제안
- 첫 질문, 마지막 질문을 제외한 모든 메세지는 loss 0으로 처리, 첫 메세지 오래 유지될 수 있도록
'MLOps' 카테고리의 다른 글
| Ubuntu에서 Grafana 설치하는 방법 (0) | 2023.07.28 |
|---|