Grounding DINO 이해하기
Title
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
https://arxiv.org/pdf/2303.05499
Introduction
많은 검출(Deteciton)모델은 사전에 준비된 데이터 한정으로만 학습이 진행되는데, 여기서 문제는 확장성 제한에 따른다. 인식해야할 물건이 바뀌거나 더 넓은 범주의 Detection을 하려면 1) 데이터 새로 모으고, 2) 레이블링 하고, 3) 모델 다시 학습하는 과정이 따른다. 4) 금액도 많이 들고, 5) 시간도 오래 소요되는것은 물론이다.
Zero-Shot Detector 는 재학습없이 새로운 물체도 인식될 수 있도록 되기를 원했고, 사용자가 입력한 prompt를 기반으로 찾게 되는 것을 의미한다.
Grounding DINO는 현재 zero-shot 객체 검출 모델에서 SOTA이다.

(왼) Prompt: 의자, (오) Prompt: 강아지 꼬리
사용자가 준 Prompt를 기반으로 객체를 잘 검출하는 것으로 보인다.
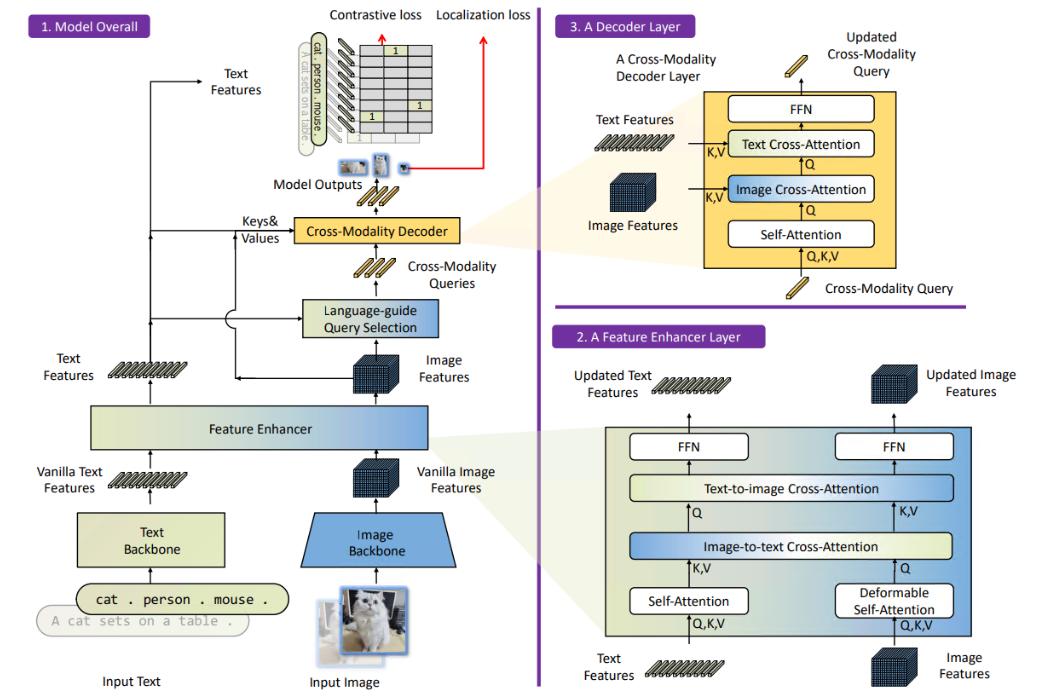
Grounding DINO의 Architecture
Grounding DINO는 기존 DINO와 GLIP 논문에서 결합된 아이디어이다.
DINO: Transformer 기반의 Detection 방법, NMS와 같은 후처리 기법이 제거된 방법
GPIP: text가 주어지고 거기에 대응되는 시각적 요소의 문맥을 이해하는 방법
1. Text Backbone and Image Backbone
- Image Backbone: Swin Transfomer (Multi-scale 이미지 feature extractor) 로 더욱 풍부한 이미지 feature 생성
- Text Backbone: BERT로 텍스트 feature 생성
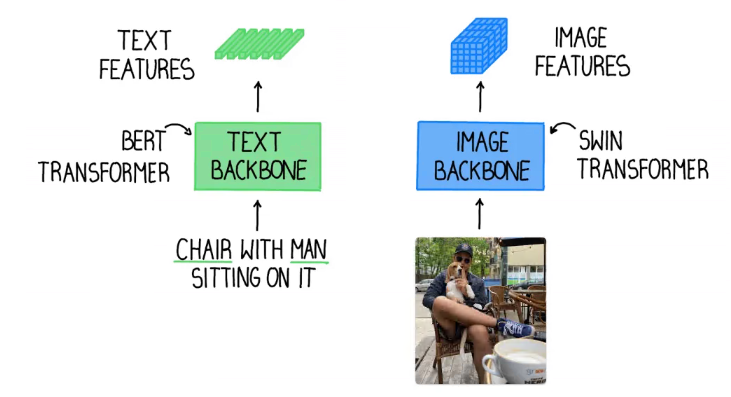
위 그림처럼 text는 text backbone에서 추출하고, image는 image backbone에서 각자 추출한다.
2. Feature Enhancer
1번 과정에서 feature가 각각 추출이 되면 멀티 모달 피쳐 통합 과정을 위해 featrue enhancer로 전달된다.
Feature Enhancer는 복수개의 feature enhancer 레이어로 구성된다.
Deformable self-attention은 이미지 피쳐를 향상시키는데 활용되고, vanilla self-attention은 텍스트 피쳐를 향상시키는데 활용된다.
3. Language-guided query selection
물체 검출에 text 입력값을 제대로 가이드 시켜주기 위해서는, language-guided query selection module이 디코더 쿼리단에서 입력 테스트가 더 관련있는 feature로 selection될 수 있게 설계됐다.
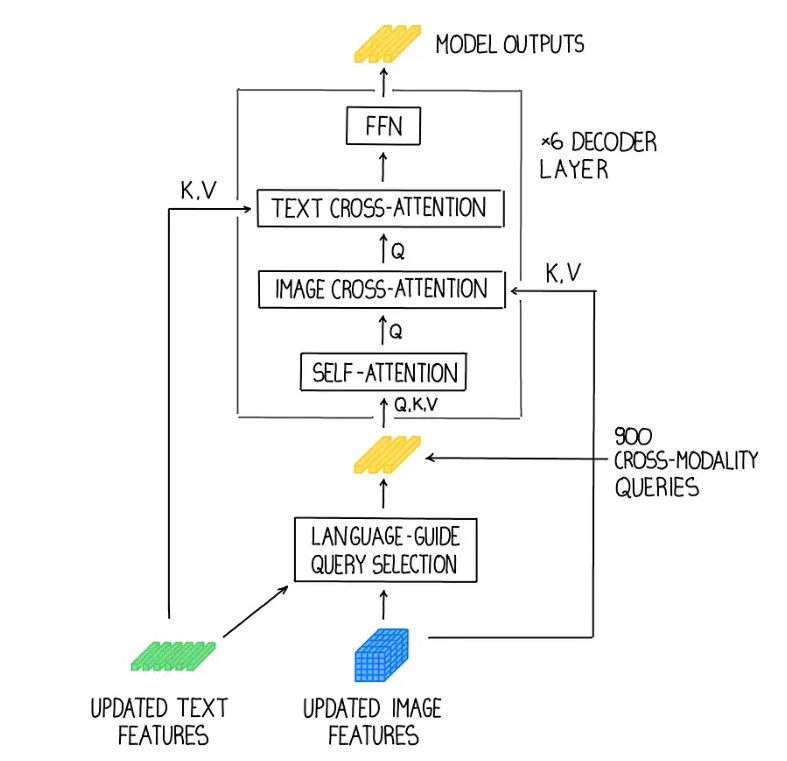
4. Cross-modality Decoder
cross-modality decorder는 이미지랑 텍스트 feature 결합하는 기능으로 구성되어지는데,
3번의 query selection으로 부터 나온 각각의 cross-modality 쿼리들이 self-attention layer로 전달된다.
다음으로 image feature는 "image cross-attention"에서 결합하고, text feature는 "text cross-attention"에서 결합한다.
마지막으로, cross-modality 디코에 레이어에서 FFN layer으로 입력된다.
각각의 decorder 레이어는 기존 DINO 디코더 레이어와 달리 추가적인 text cross-attention 레이어가 있는데, 더욱 정교한 정렬 과정을 위해서 텍스트 정보를 쿼리에 삽입해야한다.
결론은 간단히 정리되어있는데, 정교하다는 장점이 있지만 느리다는 단점이 있고,
실시간 검출로는 아직까지는 YOLO가 더 낫고, 실시간이 아니라면
GroundingDINO나 낫다라는 결론이 정리되어있습니다.
본 글은 (https://blog.roboflow.com/grounding-dino-zero-shot-object-detection/) 사이트를 참조해 요약하였습니다.
+ 추가 Summary.
1. architecture에서 그림이 잘 이해가 안된다.
'Paper' 카테고리의 다른 글
| [CVPR2024] Continual Learning 논문 리뷰 - Dataset Distillation via Disentangled Diffusion Model (작성중) (0) | 2024.06.26 |
|---|---|
| LLaMa paper Summary, 메타의 언어모델 라마(LLaMa) 논문 요약 빠르게 살펴보기 (0) | 2023.07.25 |