Paper
LLaMa paper Summary, 메타의 언어모델 라마(LLaMa) 논문 요약 빠르게 살펴보기
BrianaAI
2023. 7. 25. 10:28
안녕하세요.
오늘은 메타(구. 페이스북)에서 공개한 LLaMa 논문에 대해서 설명해보도록 하겠습니다.
논문에 대한 Summary를 찾기 쉽지 않아 직접 리뷰해본 논문이네요 :)
아주아주 간략하게 리뷰해보겠습니다.
| Paper link | https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/ |
| Code link | https://github.com/facebookresearch/llama |
Pre-trained Data

- 공공데이터만을 사용
- 각 데이터별로 다양한 전처리 기법을 적용함.
- 예) 글 내부에 영어가 아닌 다른 언어는 제외시키는 linear 모델
- Github (코드), Wikipedia (지식), Books (책), ArXiv (과학적지식), StackExchange(수준높은 Q&A), 등의 데이터 수집을 진행
- Tokenizer: BPE(Byte pair encoding) -> Sentence piece (BERT는 word piece)
- Training: 1.4T 토큰, 학습동안 모든 토큰은 only 1번만 사용됨. (위키피디아, books 도메인은 2번)
BPE 토큰화란?
1994년에 제안된 "정보 압축 알고리즘", 데이터에서 가장 많이 등장한 문자열을 병합해서 데이터를 압축하는 기법
- Tockenizer 전: aaabdaaabac (aa->Z)
- Tockenizer 후: ZabdZabac (ab->Y)
- Tockenizer 한 번 더: ZYdZYac
Architecture
- Transformer architecture 사용 (Attention is all you need) + 3개 추가 바꾼 것
- Pre-normalization[GPT3]:
- output normalization 안하고
- 훈련 안정성 높이려고, 각 트랜스포머 sub-layer의 input을 normalize
- RMSNorm (2019)
- SwiGLU [PaLM]
- ReLU 대신 SwiGLU로 대신 (성능 향상 목적으로)
- PaLM의 4d 대신에 2/3*4d 차원 사용
- Rotary Embeddings [GPTNeo]
- absolute positional embedding 제거
- rotary positional embedding 추가 (매 layer 마다)
- Pre-normalization[GPT3]:
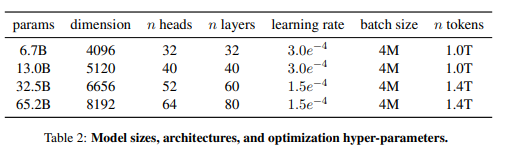

Training
- 2048 A100에서 21일간 훈련 진행.
- 근데 시간 단축하기 위한 수많은 노력들이 들어있음.
- AdamW, 코사인 훈련 스케쥴러
- 캐쥬얼 멀티헤드 어텐션
- 활성함수 수 줄이기
Result
1) Common Sense Reasoning
- BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC, OpenBookQA => 의미 모호한 대명사 찾기, 객관식 등
- LLaMa-65B > Chinchilla-70B (BoolQ 빼고 다 높음.)
- LLaMa-65B > PaLM-540B (BoolQ, WinoGrande 빼고 다 높음.)
- LLaMa-13B > GPT-3: 대부분 높다. 10배나 크기가 작은데
2) Closed-book Question Answering
- Zero-shot, few-shot 모두 LLaMa-65B 좋고, LLaMa-13B gpt-3나 chinchilla보다 5-10배나 작은데 견줄만하다.
=> 쭉 정리하다보니 다 LLaMa 좋거나 견줄만한 성능 나왔다. 그래서 모델의 크기 대비 성능 유사 혹은 그 이상

다시 정리하면,
1) Tocken 전처리
2) Transformer + 3개 바꾼거
3) Training 속도 향상시킨거
4) public data 쓴거
4가지로 정리할 수 있을 것 같습니다 :)
* Reference
[1] BPE: https://ratsgo.github.io/nlpbook/docs/preprocess/bpe/